近期,一項(xiàng)創(chuàng)新的人工智能技術(shù)引起了廣泛關(guān)注。據(jù)一項(xiàng)4月4日發(fā)布的最新研究顯示,該技術(shù)采用了一種獨(dú)特的遞歸架構(gòu),使得模型在推理過程中能夠自我修正輸出,極大地提升了準(zhǔn)確性和效率。
這項(xiàng)名為SPCT的技術(shù)分為兩個(gè)階段實(shí)施。在第一階段,即冷啟動(dòng)階段,通過拒絕式微調(diào),讓模型適應(yīng)不同類型的輸入,并以正確的格式生成原則和點(diǎn)評內(nèi)容。隨后進(jìn)入第二階段,即基于規(guī)則的在線強(qiáng)化學(xué)習(xí)階段,這一階段采用規(guī)則獎(jiǎng)勵(lì)機(jī)制,鼓勵(lì)模型生成更加精準(zhǔn)的原則和點(diǎn)評,從而增強(qiáng)了推理階段的可擴(kuò)展性。
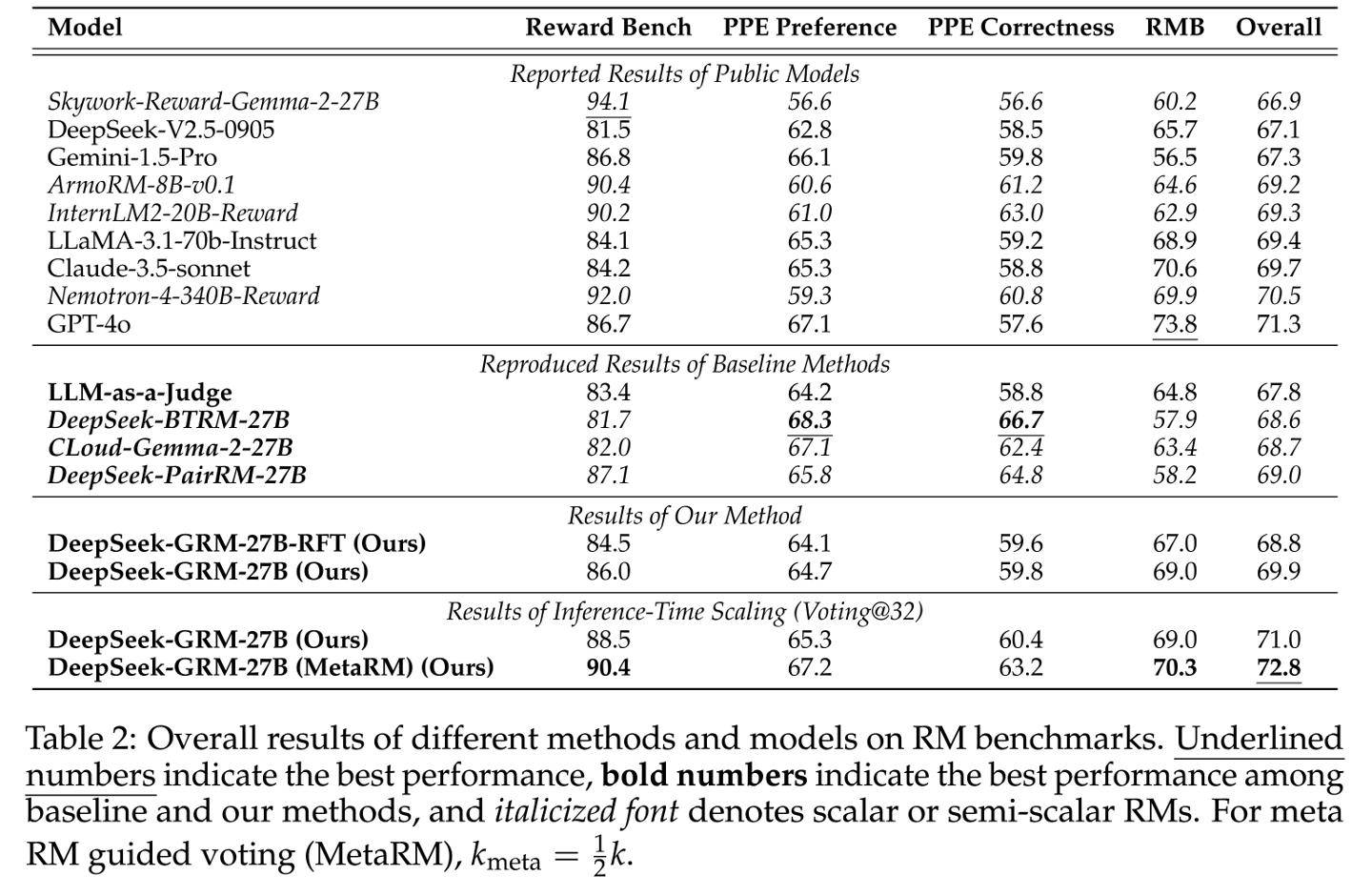
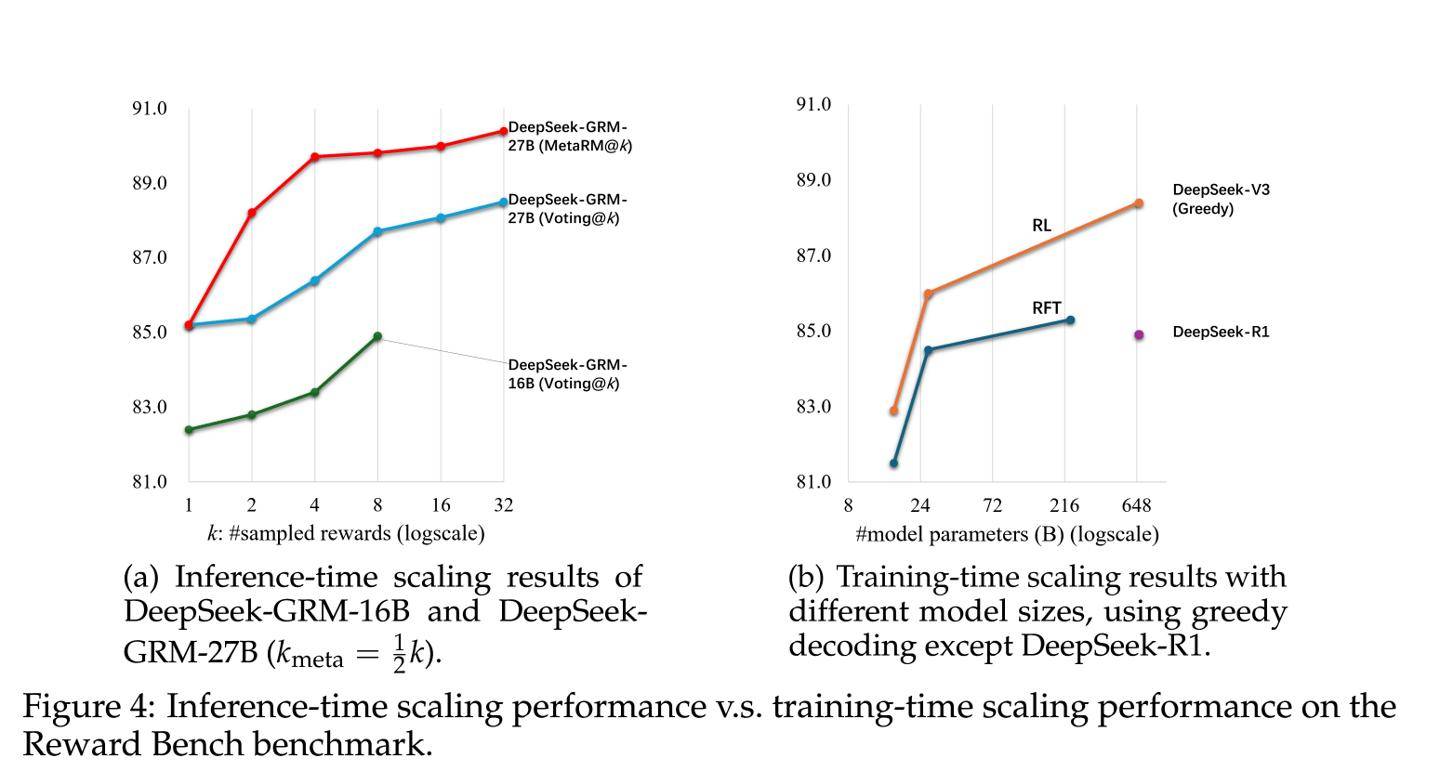
在實(shí)際測試中,使用了擁有270億參數(shù)的DeepSeek-GRM模型。通過每查詢32次采樣的推理計(jì)算,該模型的表現(xiàn)達(dá)到了671B規(guī)模模型的性能水平。這一硬件感知設(shè)計(jì)融合了混合專家系統(tǒng)(MoE),支持高達(dá)128k token的上下文窗口,并且單查詢延遲僅為1.4秒,表現(xiàn)出色。
研究報(bào)告進(jìn)一步指出,SPCT技術(shù)顯著降低了高性能模型的部署成本。以DeepSeek-GRM模型為例,其訓(xùn)練成本約為1.2萬美元(按當(dāng)前匯率約合87871元人民幣),在MT-Bench測試中的得分高達(dá)8.35。相比之下,擁有340B參數(shù)的Nemotron-4模型需要120萬美元的訓(xùn)練成本才能獲得8.41的得分,而OpenAI的GPT-4o模型,盡管得分高達(dá)8.72,但其訓(xùn)練成本更是高達(dá)630萬美元(按當(dāng)前匯率約合4613.2萬元人民幣),是DeepSeek-GRM成本的525倍之多。
SPCT技術(shù)還帶來了其他顯著優(yōu)勢。據(jù)研究團(tuán)隊(duì)介紹,該技術(shù)減少了90%的人工標(biāo)注需求,并且在能耗方面相比傳統(tǒng)方法降低了73%。這一突破為實(shí)時(shí)機(jī)器人控制等動(dòng)態(tài)場景提供了新的可能性,預(yù)示著人工智能技術(shù)在未來將有更加廣泛的應(yīng)用。