近期,科技界傳來(lái)了一則關(guān)于meta公司的最新進(jìn)展。據(jù)marktechpost報(bào)道,meta成功推出了J1系列模型,該系列模型在準(zhǔn)確性和公平性方面取得了顯著突破,這得益于其獨(dú)特的強(qiáng)化學(xué)習(xí)和合成數(shù)據(jù)訓(xùn)練策略。
在大型語(yǔ)言模型(LLM)逐漸承擔(dān)更多評(píng)估與判斷任務(wù)的大背景下,meta的J1模型應(yīng)運(yùn)而生。這種被稱為“LLM-as-a-Judge”的模式,使得AI模型能夠像法官一樣審查其他語(yǔ)言模型的輸出,成為強(qiáng)化學(xué)習(xí)、基準(zhǔn)測(cè)試和系統(tǒng)對(duì)齊的得力助手。J1模型通過(guò)內(nèi)部鏈?zhǔn)酵评恚╟hain-of-thought reasoning)來(lái)模擬人類思考過(guò)程,特別擅長(zhǎng)處理數(shù)學(xué)解題、倫理推理和用戶意圖解讀等復(fù)雜任務(wù),同時(shí)支持跨語(yǔ)言和領(lǐng)域的驗(yàn)證,極大地推動(dòng)了語(yǔ)言模型開發(fā)的自動(dòng)化和擴(kuò)展性。
然而,“LLM-as-a-Judge”模式也面臨著一些挑戰(zhàn),如一致性差、推理深度不足以及位置偏見等問題。傳統(tǒng)的評(píng)估方法往往依賴基本指標(biāo)或靜態(tài)標(biāo)注,難以有效應(yīng)對(duì)主觀或開放性問題。大規(guī)模收集人工標(biāo)注數(shù)據(jù)不僅成本高昂,而且耗時(shí)費(fèi)力,限制了模型的泛化能力。針對(duì)這些問題,meta的GenAI和FAIR團(tuán)隊(duì)研發(fā)了J1模型,旨在通過(guò)創(chuàng)新技術(shù)解決現(xiàn)有難題。
J1模型的訓(xùn)練過(guò)程采用了強(qiáng)化學(xué)習(xí)框架,利用可驗(yàn)證的獎(jiǎng)勵(lì)信號(hào)進(jìn)行學(xué)習(xí)。為了構(gòu)建數(shù)據(jù)集,團(tuán)隊(duì)精心挑選了22000個(gè)合成偏好對(duì),其中包括17000個(gè)WildChat語(yǔ)料和5000個(gè)數(shù)學(xué)查詢。通過(guò)這些數(shù)據(jù),訓(xùn)練出了J1-Llama-8B和J1-Llama-70B兩款模型。團(tuán)隊(duì)還引入了Group Relative Policy Optimization(GRPO)算法,簡(jiǎn)化了訓(xùn)練流程,并通過(guò)位置無(wú)關(guān)學(xué)習(xí)(position-agnostic learning)和一致性獎(jiǎng)勵(lì)機(jī)制有效消除了位置偏見。
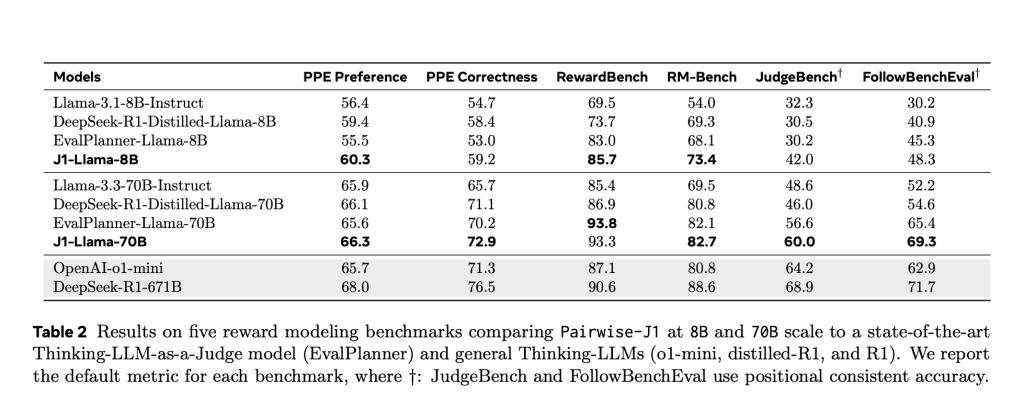
J1模型在判斷格式上展現(xiàn)出極高的靈活性和通用性,支持成對(duì)判斷、評(píng)分和單項(xiàng)評(píng)分等多種格式。在測(cè)試階段,J1模型表現(xiàn)出色,尤其是在PPE基準(zhǔn)測(cè)試中,J1-Llama-70B的準(zhǔn)確率高達(dá)69.6%,超過(guò)了DeepSeek-GRM-27B(67.2%)和evalPlanner-Llama-70B(65.6%)。即使是較小的J1-Llama-8B模型,也以62.2%的成績(jī)擊敗了evalPlanner-Llama-8B(55.5%)。
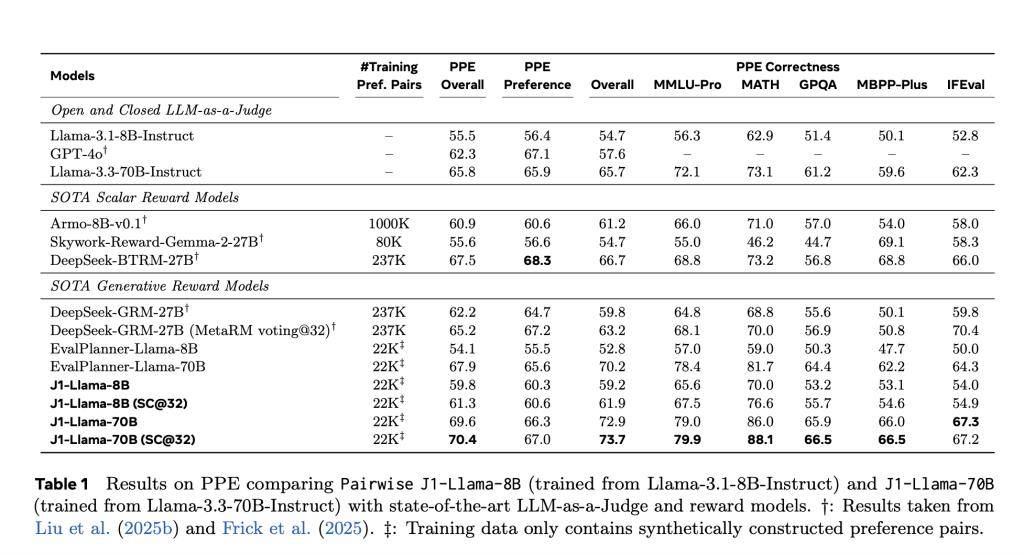
J1模型還在RewardBench、JudgeBench等多個(gè)基準(zhǔn)測(cè)試中表現(xiàn)出色,證明了其在可驗(yàn)證和主觀任務(wù)上的強(qiáng)大泛化能力。這些測(cè)試結(jié)果表明,推理質(zhì)量而非數(shù)據(jù)量,才是判斷模型精準(zhǔn)度的關(guān)鍵因素。J1模型的推出,不僅為meta在語(yǔ)言模型領(lǐng)域樹立了新的標(biāo)桿,也為整個(gè)AI行業(yè)的發(fā)展帶來(lái)了新的啟示。
隨著J1模型的廣泛應(yīng)用和持續(xù)優(yōu)化,我們有理由相信,未來(lái)AI模型在評(píng)估與判斷任務(wù)中將展現(xiàn)出更加卓越的性能和更加廣泛的應(yīng)用前景。這一創(chuàng)新成果不僅推動(dòng)了meta在AI領(lǐng)域的技術(shù)進(jìn)步,也為全球科技界樹立了新的典范。