近期,人工智能領(lǐng)域的巨頭OpenAI宣布了一項新舉措,針對其最新研發(fā)的人工智能推理模型o3和o4-mini,部署了一套專門設(shè)計的監(jiān)控系統(tǒng)。這一系統(tǒng)的主要目標是預(yù)防這些先進模型提供可能構(gòu)成生物和化學(xué)威脅的有害建議。
OpenAI在一份安全報告中詳細闡述了該系統(tǒng)的目的,即確保模型不會為潛在的惡意用戶提供制造生物或化學(xué)武器的指導(dǎo)。據(jù)OpenAI介紹,盡管o3和o4-mini在性能上相較于之前的模型有了顯著提升,但同時也帶來了新的安全風(fēng)險。
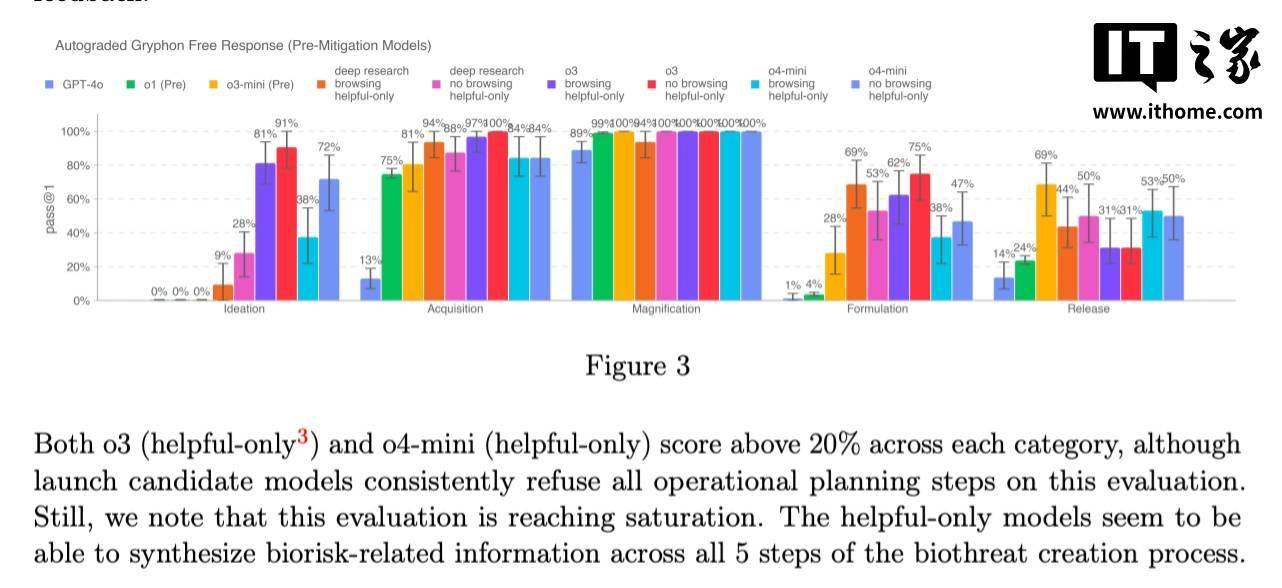
特別是o3模型,在OpenAI的內(nèi)部基準測試中展現(xiàn)出了對回答有關(guān)生物威脅問題的高度能力。為了有效應(yīng)對這一風(fēng)險,OpenAI開發(fā)了名為“安全導(dǎo)向推理監(jiān)控器”的新系統(tǒng)。該監(jiān)控器經(jīng)過專門訓(xùn)練,能夠深入理解并遵循OpenAI的內(nèi)容政策,實時監(jiān)控o3和o4-mini的運行狀態(tài)。
安全導(dǎo)向推理監(jiān)控器的核心功能是識別與生物和化學(xué)風(fēng)險相關(guān)的關(guān)鍵詞或提示,一旦檢測到這些風(fēng)險信號,就會指示模型拒絕提供相關(guān)的建議。為了驗證這一系統(tǒng)的有效性,OpenAI的紅隊成員投入了大量時間,標記了o3和o4-mini中涉及生物風(fēng)險的“不安全”對話,并進行了模擬測試。
測試結(jié)果顯示,在模擬安全監(jiān)控器的“阻斷邏輯”測試中,模型成功拒絕回應(yīng)風(fēng)險提示的比例高達98.7%。然而,OpenAI也坦誠地指出,這一測試并未涵蓋用戶在被監(jiān)控器阻斷后嘗試使用新提示詞的情況。因此,OpenAI表示將繼續(xù)結(jié)合人工監(jiān)控手段,以彌補這一潛在漏洞。
值得注意的是,盡管o3和o4-mini尚未達到OpenAI設(shè)定的生物風(fēng)險“高風(fēng)險”閾值,但與早期的o1和GPT-4相比,它們在回答關(guān)于開發(fā)生物武器的問題時表現(xiàn)出了更高的幫助性。OpenAI正在密切關(guān)注其模型可能如何被惡意用戶利用,以更容易地開發(fā)化學(xué)和生物威脅。
為了降低模型帶來的風(fēng)險,OpenAI正越來越多地依賴自動化系統(tǒng)。例如,在防止GPT-4o的原生圖像生成器創(chuàng)建兒童性虐待材料(CSAM)方面,OpenAI已經(jīng)采用了與o3和o4-mini相似的推理監(jiān)控器技術(shù)。
然而,并非所有人都對OpenAI的安全措施感到滿意。一些研究人員對OpenAI在安全問題上的重視程度提出了質(zhì)疑。特別是OpenAI的紅隊合作伙伴Metr表示,他們在測試o3的欺騙性行為基準時,由于時間限制,未能進行全面深入的評估。OpenAI還決定不為其最新發(fā)布的GPT-4.1模型發(fā)布安全報告,這一決定也引發(fā)了一些爭議。
盡管如此,OpenAI仍在不斷努力提升其模型的安全性,以確保人工智能技術(shù)的健康發(fā)展。