OpenAI近期宣布了一項旨在提升透明度的重大舉措:將更頻繁地公開其內部人工智能模型的安全評估詳情。這一決定伴隨著“安全評估中心”網頁的正式上線,該網頁于本周三正式對公眾開放。
該安全評估中心將作為一個持續更新的平臺,展示OpenAI模型在多個關鍵安全領域的表現,包括有害內容的生成、模型越獄風險以及幻覺現象等。OpenAI在一份官方博客文章中闡述,此舉意在隨著人工智能評估科學的進步,分享其在提升模型可擴展性和安全評估方法方面的最新進展。
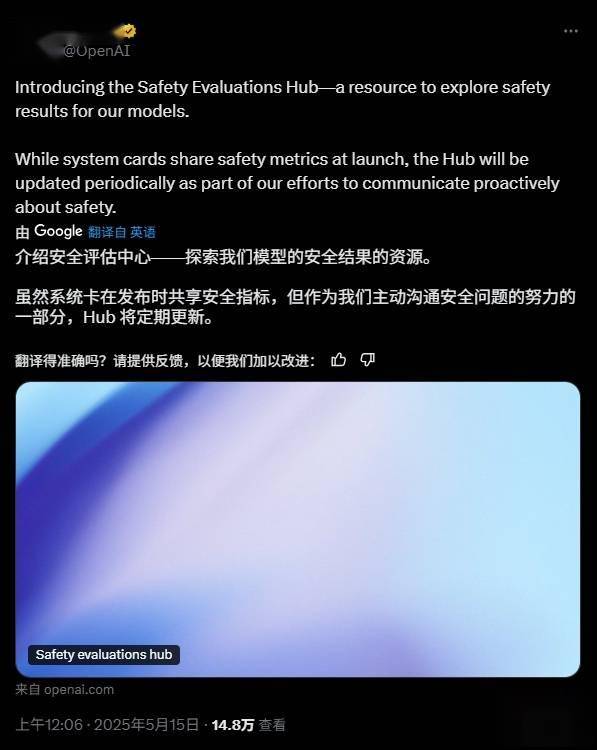
OpenAI承諾,未來將在每次重大模型更新后,及時更新安全評估中心的內容,確保用戶能夠實時了解OpenAI系統的安全性能變化。公司強調,此舉不僅是為了提升用戶對自身系統的信任度,更是為了推動整個行業在透明度方面的共同進步。OpenAI還透露,未來可能會在安全評估中心增加更多評估項目,以全面覆蓋模型的各種潛在風險。
此前,OpenAI曾因其部分旗艦模型的安全測試流程過快以及未發布其他模型的技術報告而受到倫理學家的批評。公司首席執行官山姆·奧爾特曼也一度因被指在模型安全審查問題上誤導公司高管而引發爭議。這些事件無疑對OpenAI的聲譽造成了一定影響。
值得注意的是,就在上個月末,OpenAI不得不撤回對ChatGPT默認模型GPT-4o的一次更新。原因是用戶反饋稱,更新后的模型回應方式過于“諂媚”,甚至對一些有問題的、危險的決策和想法表示贊同。這一事件引發了廣泛關注和討論,也促使OpenAI采取了一系列修復和改進措施。
為了預防類似事件的再次發生,OpenAI決定為部分模型引入一個可選的“alpha階段”。在這一階段,部分ChatGPT用戶將有機會在模型正式發布前進行測試并提供反饋。這一舉措旨在通過用戶的實際使用經驗,及時發現并修復模型可能存在的問題,從而提升模型的穩定性和安全性。