近期,一項由蘋果公司與杜克大學攜手推出的創新強化學習方法“交錯推理”,在人工智能領域掀起了波瀾。該方法旨在顯著增強大語言模型的推理能力,為復雜問題的解決提供了新的視角。
在探討這一突破之前,我們不得不提及當前大語言模型在處理多步驟復雜問題時所面臨的挑戰。它們往往遵循一種線性的“思考-回答”模式,雖然邏輯清晰,但響應速度較慢,且在推理鏈的任一環節出錯都可能影響最終答案的準確性。這種模式與人類的交流方式大相徑庭,人類傾向于在思考過程中逐步表達想法,而模型則傾向于在完成整個推理后才給出答案,這在一定程度上限制了其效率和互動性。
為了打破這一僵局,“交錯推理”應運而生。該方法的核心在于,在模型的推理過程中,巧妙地交替進行內部計算和輸出中間答案的操作,從而大幅提升響應速度和實用性。為了實現這一目標,研究團隊設計了一個基于強化學習的訓練框架,其中嵌入了特定的指示標簽,這些標簽能夠引導模型在達到關鍵推理節點時輸出階段性成果。
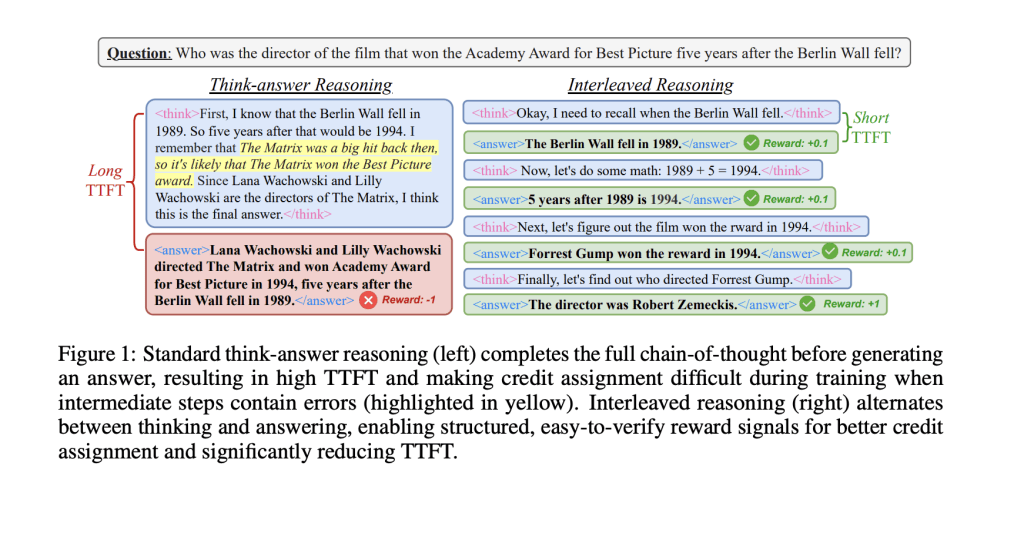
為了確保模型在追求局部輸出效率的同時,不犧牲整體推理的準確性,研究團隊精心構建了一套基于規則的獎勵機制。該機制綜合考慮了格式合規性、最終準確率以及條件性中間準確率等多個維度,以確保模型在推理過程中的每一步都能得到恰當的激勵。
實驗數據表明,“交錯推理”在Qwen2.5模型(包括1.5B和7B參數版本)上取得了顯著成效。與傳統方法相比,該方法的響應速度提升了超過80%,推理準確率也提高了近19.3%。更令人振奮的是,盡管模型僅在問答類和邏輯類數據集上進行了訓練,但它在MATH、GPQA和MMLU等更具挑戰性的任務中也展現出了強大的泛化能力。
研究團隊還嘗試了多種獎勵機制,包括全或無獎勵、部分積分獎勵及時間折扣獎勵等。結果顯示,條件性獎勵和時間折扣獎勵的效果最為突出,遠遠超越了傳統訓練方式。
“交錯推理”的提出,不僅為提升大語言模型在復雜推理任務中的表現提供了一條切實可行的技術路徑,也為未來模型的設計與優化提供了新的思路。這一創新成果無疑將推動人工智能領域向更加高效、智能的方向發展。