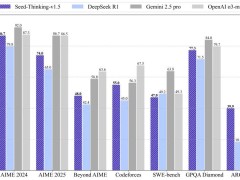
近期,LMArena更新了大型語言模型的排名,引發了一場關于meta最新發布的開源大模型Llama-4-Maverick真實性能的廣泛討論。此前,Llama-4-Maverick在LMArena的Chatbot Arena LLM排行榜上高居第二,僅次于Gemini 2.5 Pro。然而,這一排名近日卻發生了戲劇性的變化,Llama-4-Maverick直線下降至第32名。
這一變化源于開發者對meta提供給LMArena的Llama 4版本產生質疑。有開發者指出,meta提交給LMArena的版本與向社區公開的開源版本存在顯著差異,懷疑meta為了刷榜而提供了“特供版”。這一質疑迅速在開發者社區中發酵,引發了廣泛的關注和討論。
為了回應這些質疑,Chatbot Arena官方于4月8日發文確認了開發者的猜測。官方表示,meta首次提交給他們的Llama-4-Maverick版本是一個實驗性聊天優化版本,即Llama-4-Maverick-03-26-Experimental。該版本在LMArena上取得了不錯的排名,但隨后曝光的開源版本卻表現平平。
隨著更多關于開源版Llama-4-Maverick性能的信息曝光,該模型的口碑急劇下滑。開發者發現,開源版Llama-4-Maverick在LMArena的排名遠低于Gemini 2.5 Pro、GPT4o等競爭對手,甚至連基于上一代Llama 3.3改造的模型都不如。這一發現進一步加劇了開發者對meta刷榜行為的質疑。

針對這一爭議,meta方面給出了回應。一位meta發言人表示,meta確實嘗試了“各種類型的定制變體”,其中Llama-4-Maverick-03-26-Experimental是針對聊天優化的版本。該發言人稱,這一版本在LMArena上表現不錯,但meta隨后發布了開源版本,并期待開發者根據自己的使用案例進行定制。
然而,盡管meta給出了回應,但開發者社區的質疑并未因此平息。許多開發者認為,針對基準測試調整模型不僅具有誤導性,還使得他們難以準確預測該模型在不同場景下的表現。這一事件再次引發了關于AI模型性能評估和排名的廣泛討論。
在這場爭議中,LMArena的排名也受到了質疑。有開發者指出,盡管LMArena是一個重要的基準測試平臺,但其排名結果并非衡量AI模型性能的最可靠指標。這一觀點得到了許多開發者的認同。
隨著討論的深入,越來越多的開發者開始關注AI模型的實用性和場景適應性。他們認為,真正的AI模型應該能夠在各種實際場景中表現出色,而不僅僅是在某個特定的基準測試上取得高分。這一觀點逐漸成為了開發者社區的主流聲音。