阿里巴巴于近日宣布了一項重大開源舉措,正式推出了Qwen3-Embedding系列模型,這一系列模型專注于文本表征、檢索與排序任務,是基于Qwen3基礎模型深度訓練而來。
Qwen3-Embedding系列模型在多項基準測試中展現了令人矚目的性能。據官方數據顯示,在MTEB多語言Leaderboard榜單上,該系列的8B參數規模Embedding模型以70.58分的成績位列榜首,這一成績不僅超越了眾多商業API服務,也彰顯了其在多語言文本處理方面的卓越實力。
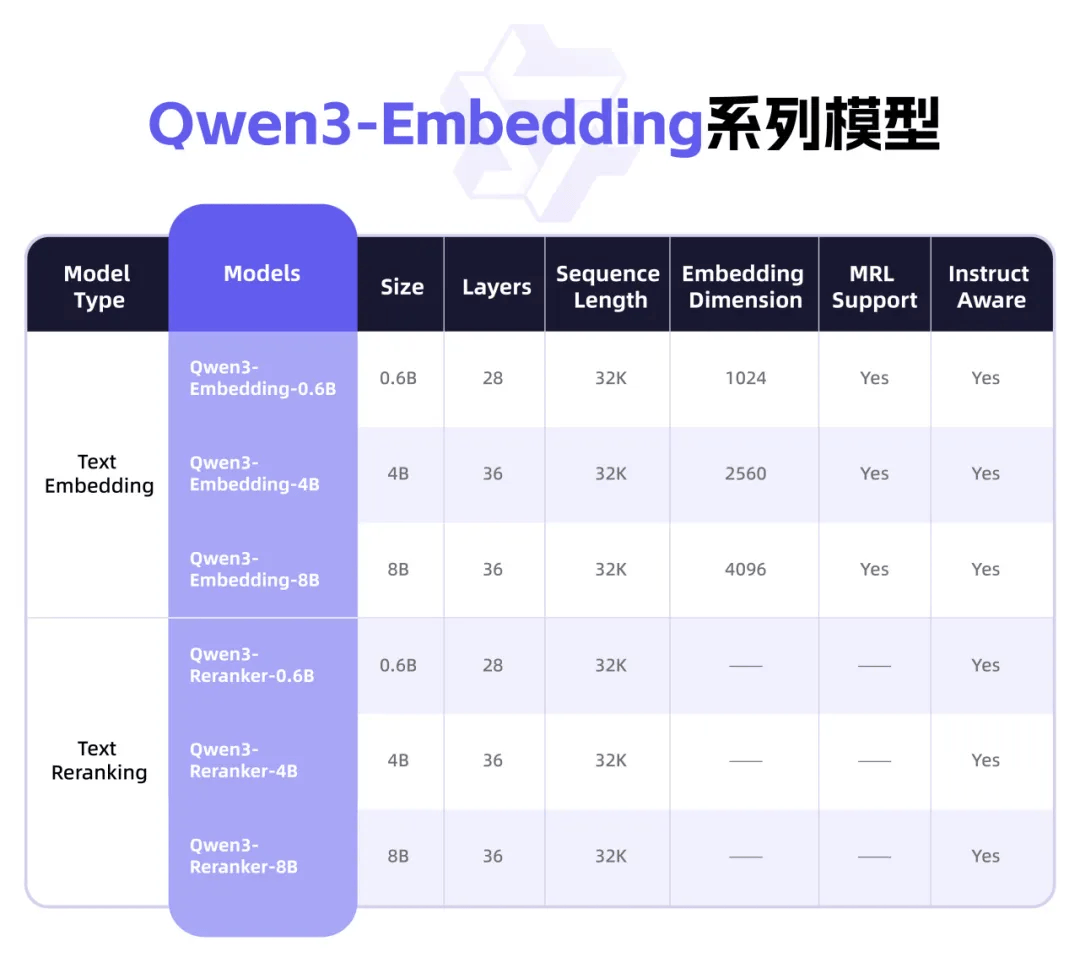
這一系列模型的特點之一是具備出色的泛化性。在多個下游任務評估中,Qwen3-Embedding系列均達到了行業領先水平。特別是在文本檢索場景中,其排序模型能夠顯著提升搜索結果的相關性,為用戶帶來更加精準的檢索體驗。
Qwen3-Embedding系列還提供了靈活的模型架構。從0.6B到8B參數規模,該系列提供了三種不同的模型配置,以滿足不同場景下的性能與效率需求。開發者可以根據實際需求,靈活組合表征與排序模塊,實現功能的定制化擴展。
在定制化特性方面,Qwen3-Embedding系列同樣表現出色。它允許用戶根據實際需求調整表征維度,有效降低應用成本。同時,該系列還支持用戶自定義指令模板,以提升特定任務、語言或場景下的性能表現。這一特性使得Qwen3-Embedding系列能夠更好地適應各種復雜的應用場景。
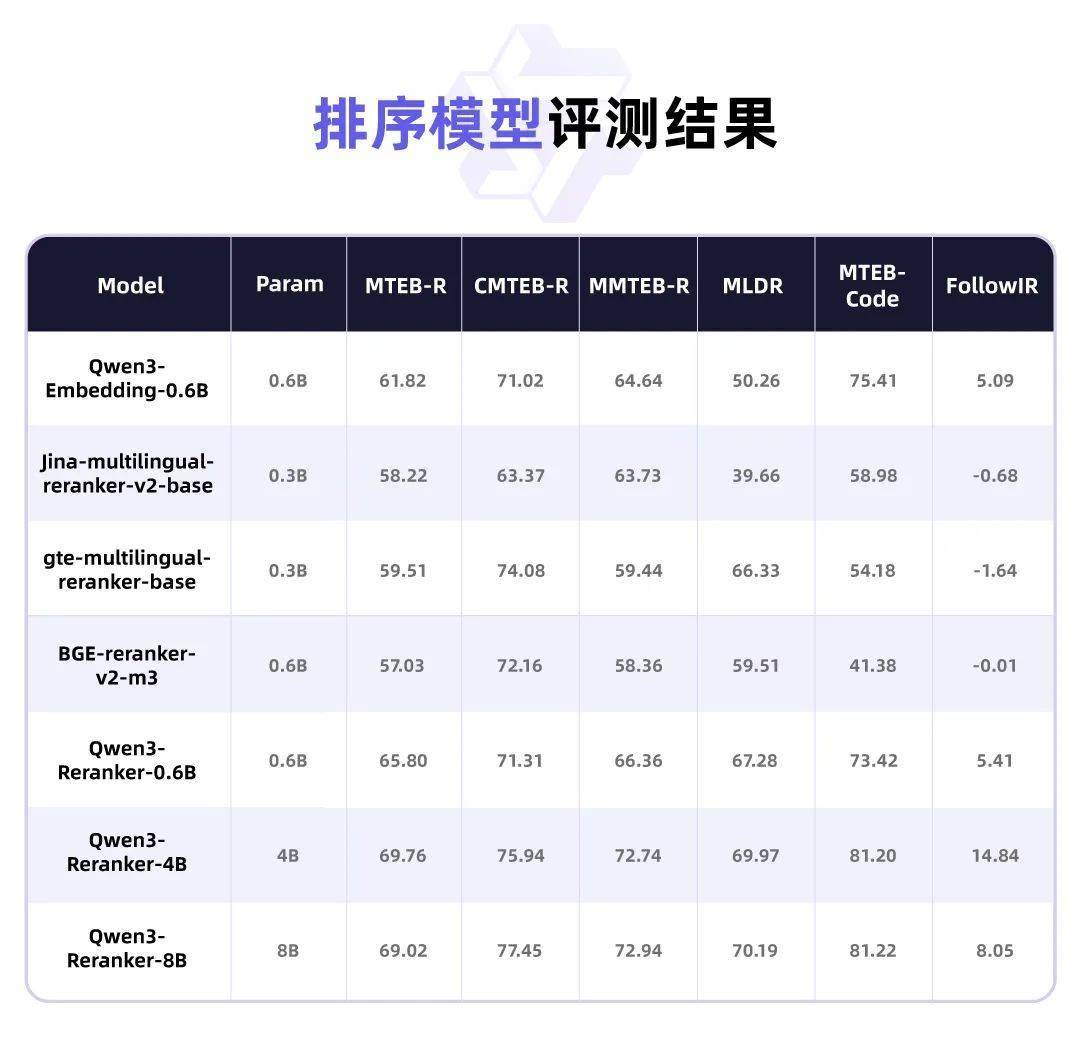
Qwen3-Embedding系列還支持超過100種語言,涵蓋主流自然語言及多種編程語言。這一特性使得該系列模型在多語言場景下具備強大的處理能力,無論是多語言文本檢索還是跨語言文本匹配,都能表現出色。
在模型使用方面,Embedding模型主要接收單段文本作為輸入,通過取模型最后一層“EOS”標記對應的隱藏狀態向量,作為輸入文本的語義表示。而Reranker模型則接收文本對(如用戶查詢與候選文檔)作為輸入,利用單塔結構計算并輸出兩個文本的相關性得分。這一設計使得Qwen3-Embedding系列在文本檢索和排序任務中能夠發揮出色的性能。
目前,Qwen3-Embedding系列模型已經正式開源,開發者可以通過ModelScope、Hugging Face以及GitHub等平臺獲取相關資源和代碼。同時,官方還提供了詳細的技術報告,幫助開發者更好地理解和使用該系列模型。