阿里通義團(tuán)隊(duì)近日宣布了一項(xiàng)重要開(kāi)源成果——通義千問(wèn)3向量模型系列Qwen3-Embedding(簡(jiǎn)稱千問(wèn)3向量模型)。這一全新系列模型的推出,標(biāo)志著阿里在AI技術(shù)領(lǐng)域的又一次重大突破。
千問(wèn)3向量模型以千問(wèn)3大模型為基礎(chǔ),經(jīng)過(guò)精心優(yōu)化訓(xùn)練,專門(mén)針對(duì)文本表征、檢索和排序等核心任務(wù)。相較于前代模型,新模型在文本檢索、聚類、分類等關(guān)鍵性能指標(biāo)上實(shí)現(xiàn)了顯著提升,部分提升幅度高達(dá)40%以上。這一改進(jìn)無(wú)疑將為用戶帶來(lái)更加高效、準(zhǔn)確的文本處理體驗(yàn)。
在業(yè)界知名的MTEB等專項(xiàng)榜單中,千問(wèn)3向量模型表現(xiàn)搶眼。其中,Qwen3-Embedding-8B模型更是力壓群雄,超越了谷歌的Gemini Embedding、OpenAI的text-embedding-3-large以及微軟的multilingual-e5-large-instruct等頂尖模型,成功奪得同類模型的最佳性能SOTA稱號(hào)。這一榮譽(yù)不僅是對(duì)千問(wèn)3向量模型實(shí)力的認(rèn)可,也是阿里在AI領(lǐng)域深厚技術(shù)底蘊(yùn)的體現(xiàn)。
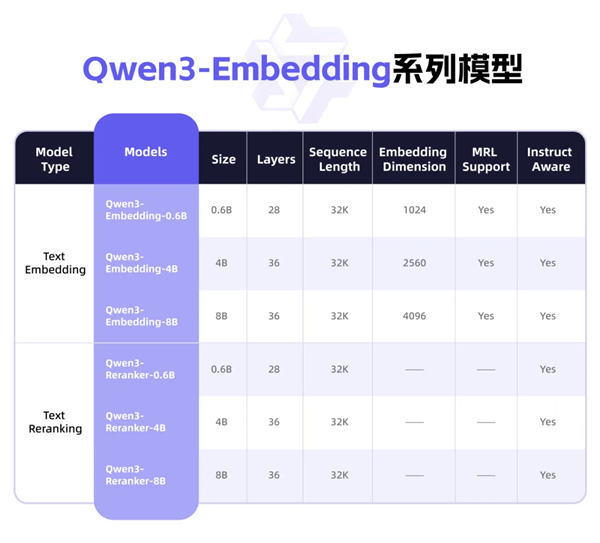
向量模型作為AI的“翻譯器”,扮演著將非結(jié)構(gòu)化信息(如文本、圖片等)轉(zhuǎn)化為機(jī)器更易理解的向量空間的重要角色。基于這一原理,千問(wèn)3向量模型能夠?qū)崿F(xiàn)對(duì)信息的高效分類、檢索和排序。為了滿足不同用戶的需求,通義團(tuán)隊(duì)通過(guò)對(duì)比訓(xùn)練、SFT、模型融合等多種方法,精心打造出包含文本嵌入模型Qwen3-Embedding和文本排序模型Qwen3-Reranker在內(nèi)的全新千問(wèn)3向量模型系列。
得益于千問(wèn)3大模型的多語(yǔ)言能力,千問(wèn)3向量模型系列也具備了強(qiáng)大的多語(yǔ)言、跨語(yǔ)言及代碼檢索能力。目前,該系列模型已率先支持超過(guò)100種語(yǔ)言,并涵蓋多種編程語(yǔ)言,為用戶提供了更加便捷、高效的跨語(yǔ)言信息檢索服務(wù)。
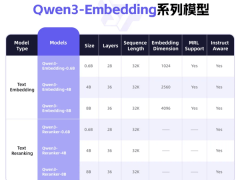
此次開(kāi)源的千問(wèn)3向量模型系列共包含9款不同尺寸的模型,包括0.6B、4B、8B等多種規(guī)格,以及GGUF版本。開(kāi)發(fā)者可以根據(jù)自己的需求選擇合適的模型,并自由組合模塊,甚至自定義向量或指令,以實(shí)現(xiàn)特定任務(wù)、語(yǔ)言和場(chǎng)景的深度優(yōu)化。這一靈活性無(wú)疑將大大拓寬千問(wèn)3向量模型的應(yīng)用場(chǎng)景和范圍。
目前,千問(wèn)3 Embedding和Reranker模型均已在魔搭社區(qū)、Hugging Face和GitHub等平臺(tái)上開(kāi)源。開(kāi)發(fā)者可以直接通過(guò)這些平臺(tái)獲取模型資源,并利用阿里云百煉提供的API服務(wù)進(jìn)行開(kāi)發(fā)和應(yīng)用。這一舉措無(wú)疑將大大降低開(kāi)發(fā)者的門(mén)檻,推動(dòng)AI技術(shù)的普及和應(yīng)用。
自4月29日千問(wèn)3大模型開(kāi)源以來(lái),該模型已在Artificial Analysis、LiveBench、LiveCodeBench、SuperClue等多個(gè)榜單上奪得全球開(kāi)源冠軍。這一連串的榮譽(yù)不僅彰顯了千問(wèn)3大模型的強(qiáng)大實(shí)力,也預(yù)示著阿里在AI領(lǐng)域?qū)⒊掷m(xù)保持領(lǐng)先地位。