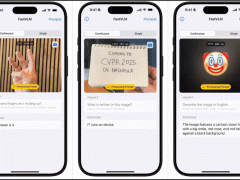
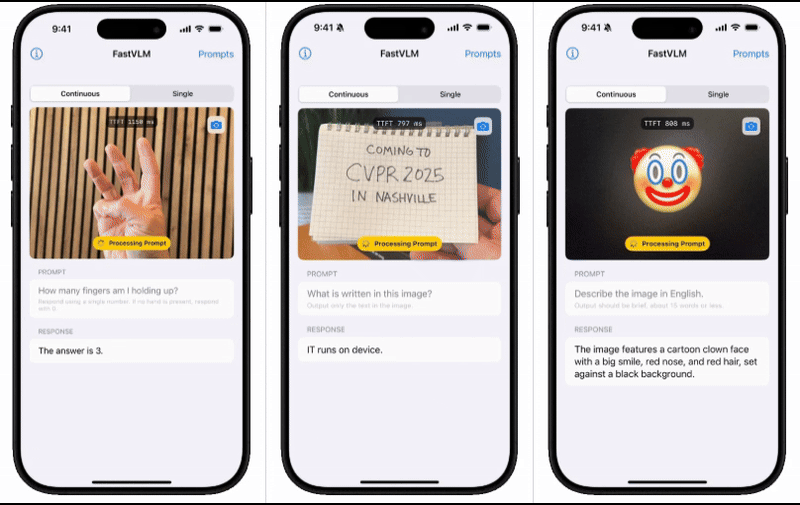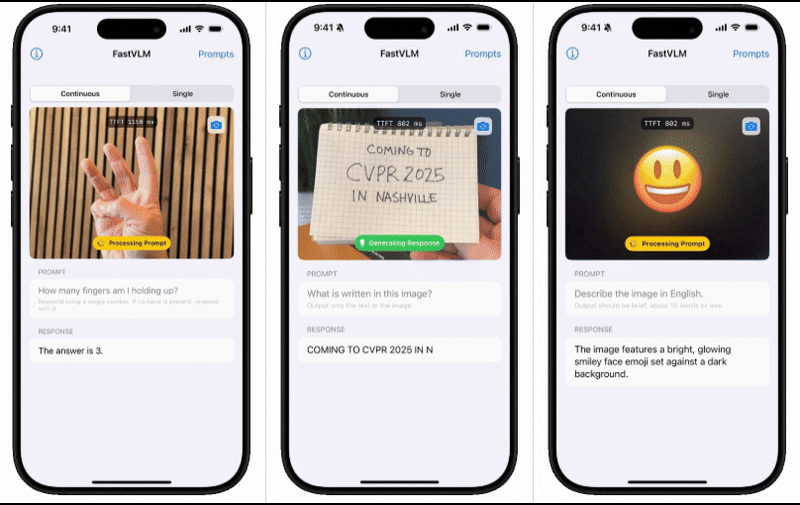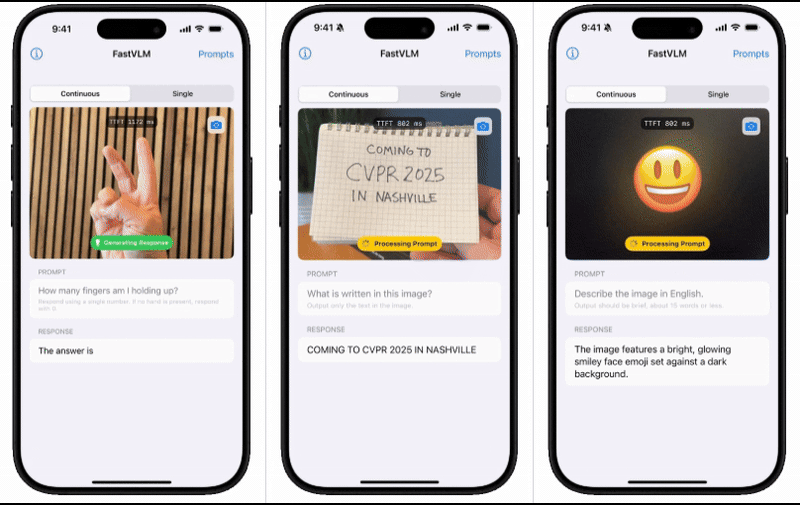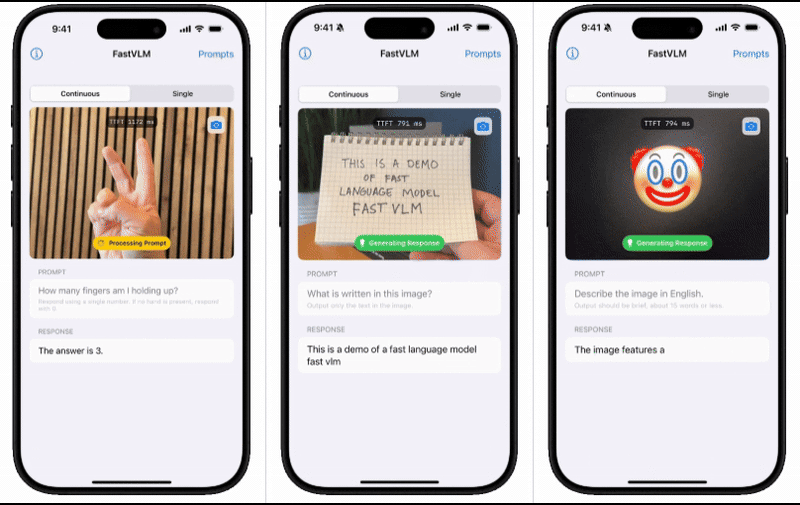
蘋果機器學習團隊近期在GitHub上掀起波瀾,他們發布并開源了一款名為FastVLM的視覺語言模型,為用戶提供0.5B、1.5B和7B三種不同規模的版本選擇。
這款模型是蘋果基于其自研的MLX框架精心打造,同時借助LLaVA代碼庫進行高效訓練。尤為FastVLM針對Apple Silicon設備的端側AI運算進行了深度優化,旨在為用戶提供更為流暢的體驗。
技術文檔詳細揭示了FastVLM的卓越性能。它在保持高精度的同時,實現了高分辨率圖像處理的近實時響應,而且所需的計算量遠低于同類模型。這一突破性的進展,無疑為視覺語言模型的應用開辟了更廣闊的空間。
FastVLM的核心競爭力在于其創新的FastViTHD混合視覺編碼器。蘋果團隊自豪地表示,這款編碼器專為高分辨率圖像設計,旨在實現高效的VLM性能。與同類模型相比,FastViTHD的處理速度提升了3.2倍,而體積卻僅為原來的3.6分之一。這一顯著的優勢,使得FastVLM在視覺語言模型領域獨樹一幟。
在具體性能對比中,FastVLM的最小模型版本展現出了驚人的表現。與LLaVA-OneVision-0.5B模型相比,FastVLM的首詞元響應速度提升了85倍,而視覺編碼器的體積則縮小了3.4倍。當搭配Qwen2-7B大語言模型版本時,FastVLM使用單一的圖像編碼器便超越了Cambrian-1-8B等近期研究成果,首詞元響應速度更是提升了7.9倍。
為了直觀展示FastVLM的性能表現,蘋果技術團隊還推出了一款配套的iOS演示應用。這款應用通過實機演示,讓用戶能夠親身體驗到移動端模型的出色表現。這一舉措無疑進一步增強了用戶對FastVLM的信心和期待。
蘋果技術團隊在介紹中表示,基于對圖像分辨率、視覺延遲、詞元數量與LLM大小的綜合效率分析,他們成功開發出了FastVLM。這款模型在延遲、模型大小和準確性之間實現了最優權衡,為用戶提供了更為高效、便捷的體驗。
展望未來,FastVLM的應用場景將十分廣泛。特別是針對蘋果正在研發的智能眼鏡類穿戴設備,FastVLM的本地化處理能力將有效支持這類設備脫離云端實現實時視覺交互。這一技術的突破,無疑為蘋果在智能穿戴設備領域的布局注入了新的活力。
MLX框架的推出進一步增強了蘋果的端側AI技術生態。這一框架允許開發者在Apple設備本地訓練和運行模型,同時兼容主流AI開發語言。這為開發者提供了更為靈活、高效的開發環境,進一步推動了蘋果端側AI技術的發展。